Page History
...
In this tutorial, we will create some UI tests as Cucumber Scenario(s)/Scenario Outline(s) and use Cypress to implement the tests in JavaScript.
...
For the purpose of this tutorial, we 'll will use a dummy website (source-code here) containing just a few pages to support login/logout kind of features; we aim to test precisely those features.
...
We need to configure Cypress to use the cypress-cucumber-preprocessor, which provides the ability of understanding to understand .feature files and also of producing to produce Cucumber JSON reports.
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
const cucumber = require('cypress-cucumber-preprocessor').default
/**
* @type {Cypress.PluginConfig}
*/
module.exports = (on, config) => {
// `on` is used to hook into various events Cypress emits
// `config` is the resolved Cypress config
on('file:preprocessor', cucumber())
}
|
...
In Cypress' main configuration file, we define the base URL of the website under test, the regex of the files that contain the test scenarios (i.e. <...>.feature files). Other options may be defined (defined e.g for bypassing chromeWebSecurity, additional reporters, the ability to upload results to Cypress infrastructure in the cloud, etc).
...
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
{
"baseUrl": "https://robotwebdemo.herokuapp.com/",
"testFiles": "**/*.feature",
"ignoreTestFiles": [
"*.js",
"*.md"
],
"reporter": "junit",
"reporterOptions": {
"mochaFile": "test-results/test-output-[hash].xml"
},
"chromeWebSecurity": false,
"projectId": "bfi83g"
} |
Next, you may find here is an example of the contents of package.json.
...
Before moving into the actual implementation, we need to decide is which workflow we'll use: do we want to use Xray/Jira as the master for writing the declarative specification (i.e. the Gherkin based Scenarios), or do we want to manage those outside using some editor and store them in Git, for example?
...
| Info | ||
|---|---|---|
| ||
Please see Testing in BDD with Gherkin based frameworks (e.g. Cucumber) for an overview of the possible workflows. The place that you'll use to edit the Cucumber Scenarios will affect your workflow. There are teams that prefer to edit Cucumber Scenarios in Jira using Xray, while there others that prefer prefers to edit them by writing the .feature files by hand using some IDE. |
Using Jira and Xray as master
This section assumes using you will use Xray as master, i.e. the place that you'll be using to edit the specifications (e.g. the scenarios that are part of .feature files).
...
If you have it, then you can just use the "Create Test" on that issue to create the Scenario/Scenario Outline and have it automatically linked back to the Story/"requirement.".
Otherwise, you can create the Test using the standard (issue) Create action from Jira's top menu.
...
In this case, we'll create a Cucumber Test, of Cucumber Type "Scenario.".
We can fill out the Gherkin statements immediately on the Jira issue "create dialog" or we can create the Test issue first and fill out the details on the next screen, from within the Test issue. In the latter case, we can take advantage of the built-in Gherkin editor which provides auto-complete of for Gherkin steps.
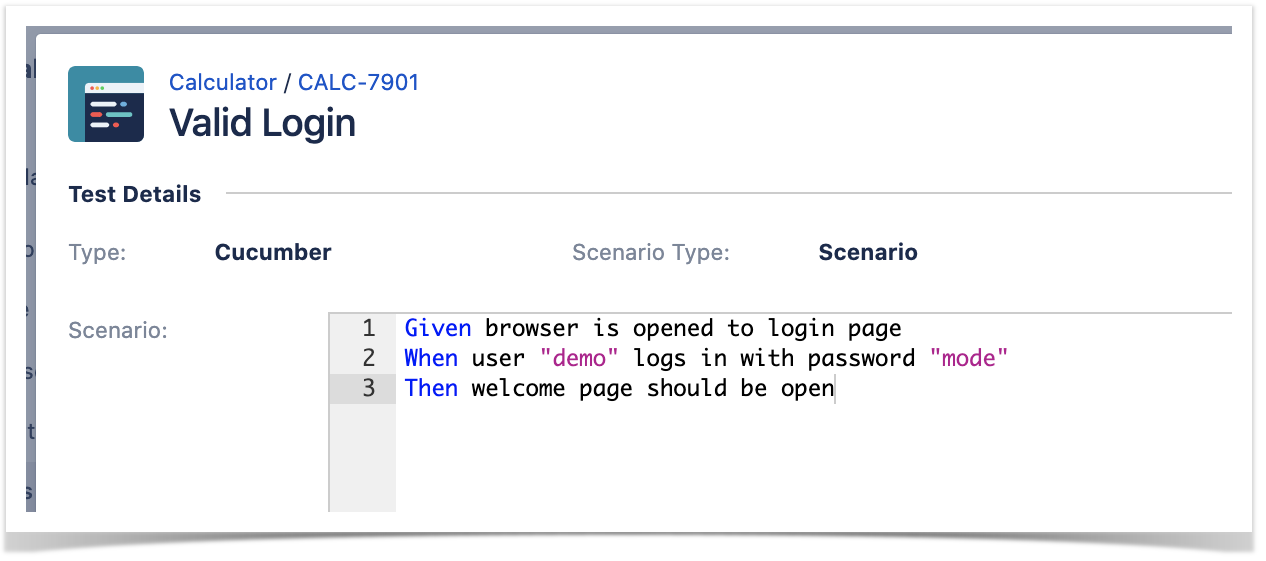
After the Test is created it will impact the coverage of related "requirement," , if any.
The coverage and the test results can be tracked in the "requirement" side (e.g. user story). In this case, you may see that coverage changed from being UNCOVERED to NOTRUN (i.e. covered and with at least one test not run).
...
The related statement's code is managed outside of Jira and stored in Git, for example.
In Cypress, tests related the test code is stored under cypress/integration directory, which itself contains several other directories. In this case, we've organized them as follows:
...
| Info | ||
|---|---|---|
| ||
To import results, you can use two different endpoints/"formats" (endpoints described in Import Execution Results - REST):
The standard cucumber endpoint (i.e. /import/execution/cucumber) is simpler but more restrictive: you cannot specify values for custom fields on the Test Execution that will be created. This endpoint creates new Test Execution issues unless the Feature contains a tag having an issue key of an existing Test Execution. The multipart cucumber endpoint will allow you to customize fields (e.g. Fix Version, Test Plan) , if you wish to do so, on the Test Execution that will be created. Note that this endpoint always creates new Test Executions (as of Xray v4.2). In sum, if you want to customize the Fix Version, Test Plan and/or Test Environment of the Test Execution issue that will be created, you'll have to use the "multipart cucumber" endpoint. |
...
Results are reflected on the covered item (e.g. Story). On its the issue screen, coverage now shows that the item is OK based on the latest testing results , that which can also be tracked within the Test Coverage panel bellow.
...
You can edit your .feature files using your IDE outside of Jira (eventually storing them in your VCS using Git, for example) alongside with the remaining test code.
In any case, you'll need to synchronize your .feature files to Jira so that you can have visibility of them and report results against them.
...
Having those to guide testing, we could then move to Cypress to describe and implement the Cucumber test scenarios.
In Cypress, tests test related code is stored inside the cypress/integration directory, which itself contains several other directories. In this case, we've organized them as follows:
...
| Info | ||
|---|---|---|
| ||
Each Scenario of each .feature will be created as a Test issue that contains unique identifiers, so that if you import once again then Xray can update the existent Test and don't create any duplicated tests. |
AfterwardAfterwards, you can export those features out of Jira, based on some criteria , so they are properly tagged with corresponding issue keys; this is important because results need to contain these references.
...
| Info | ||
|---|---|---|
| ||
To import results, you can use two different endpoints/"formats" (endpoints described in Import Execution Results - REST):
The standard cucumber endpoint (i.e. /import/execution/cucumber) is simpler but more restrictive: you cannot specify values for custom fields on the Test Execution that will be created. This endpoint creates new Test Execution issues unless the Feature contains a tag having an issue key of an existing Test Execution. The multipart cucumber endpoint will allow you to customize fields (e.g. Fix Version, Test Plan) , if you wish to do so, on the Test Execution that will be created. Note that this endpoint always creates new Test Executions (as of Xray v4.2). In sum, if you want to customize the Fix Version, Test Plan and/or Test Environment of the Test Execution issue that will be created, you'll have to use the "multipart cucumber" endpoint. |
...