Overview
With the acquisition of "Automation for Jira" app by Atlassian, Jira Cloud now provides built-in automation capabilities allowing easy implementation of automated Jira processes and workflows.
This way, users can implement rules that are triggered upon some event, executed if certain condition(s) are met and, that perform certain action(s).
Rules can also be triggered manually or may be scheduled.
Since Xray uses issue types for most of its entities, you can take advantage of it to implement some rules related to Xray.
Automation rules are available and, can be created, from the project settings, namely from the "Automation" tab.

This document highlights some examples around triggering test automation but you may implement other automation rules related to your processes.
Please note
The following examples are provided as-is, no warranties attached; use them carefully.
Please feel free to adapt them to your needs.
Note: We don't provide support for Jira Cloud's Automation capabilities; if you have doubts concerning its usage, please contact Atlassian. If you have specific needs related to Xray, feel free to reach out Xray support and share them with us.
Concepts
Jira Automation allows project administrators to implement rules that can make certain processes automated, guaranteeing efficiency and consistency.
The main concepts of Jira Automation follow a very simple approach for defining an automation rule: if a certain "thing" happens (trigger) and certain conditions are met, then execute one or more actions.
- Trigger: Triggers start the execution of a rule. Triggers can listen for events or be scheduled to run.
- manual
- upon field or workflow status changes
- upon releasing
- periodic
- ...
- Condition: Actions will only execute if all conditions preceding them pass.
- "If" statement
- Issue fields condition
- ...
- Action: Actions perform changes to a system.
- change fields on issues
- transition issues
- web request
- log
- ...
It's also possible to run actions on issues that are related to the issue that triggered the rule, using "branches".
Please note
Automation rules run asynchronously. Some actions can run in parallel but usually they're sequential. There is no interaction with the user (except if the trigger was set off manually from Jira's UI).
Usage Examples
- Generic automation of Testing processes
- Define a periodic email on Test Plan progress using Jira Automation
- Trigger a Azure DevOps pipeline
- Trigger a Bamboo plan build
- Trigger a BitBucket pipeline
- Trigger a GitHub workflow
- Trigger a GitLab workflow
- Trigger a Jenkins project build
- Trigger a TravisCI project build
Tips
Accessing network-restricted CI/CD tools
If your target system is behind a firewall or it's a local IP address, you can use ngrok tool to create a temporary tunnel to it. Please check with your IT/security team(s).
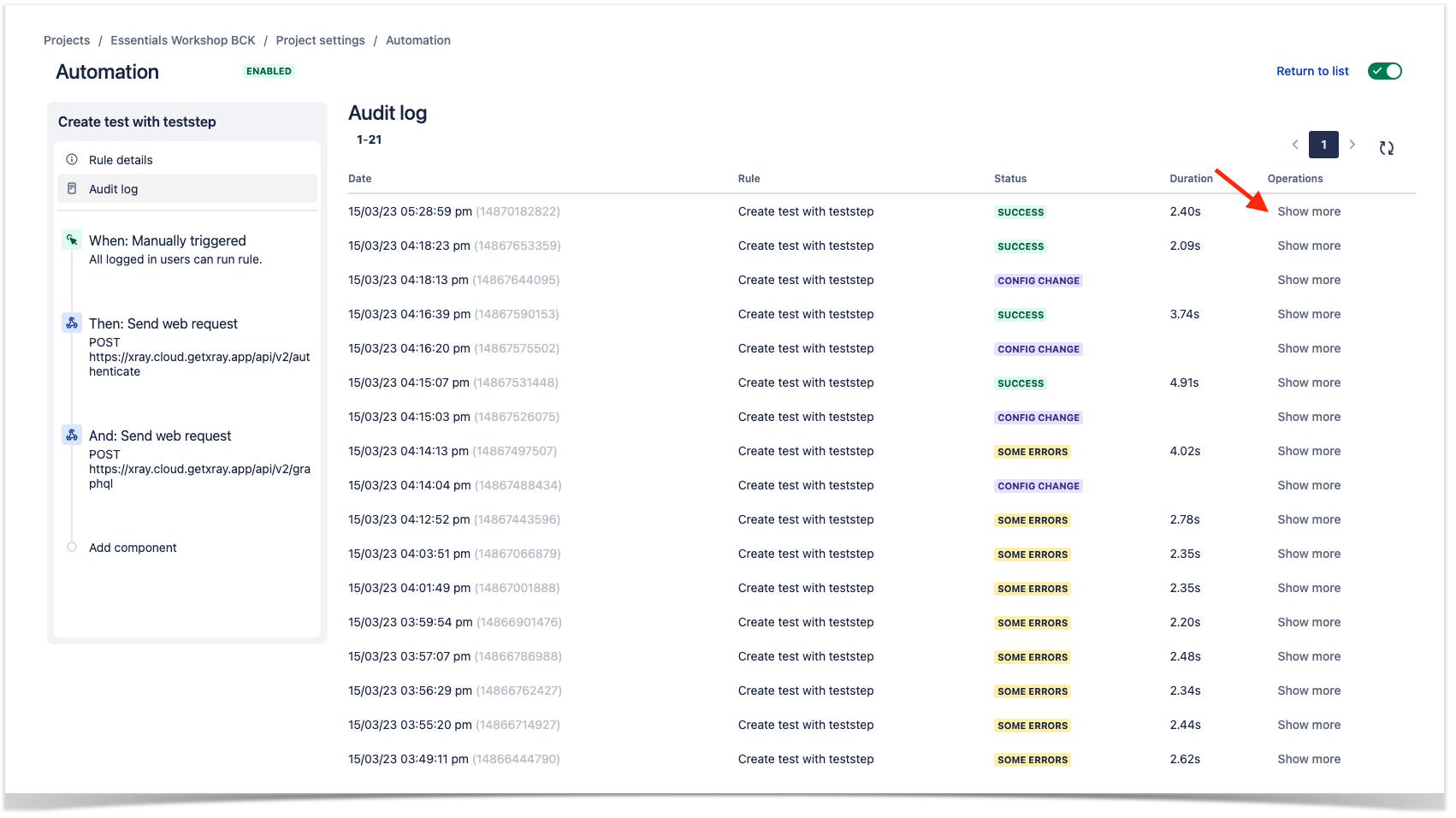
Accessing audit log of Jira automation
If you wan to have more information about the rule execution you can click over the link presented in the "Recent rules executions".
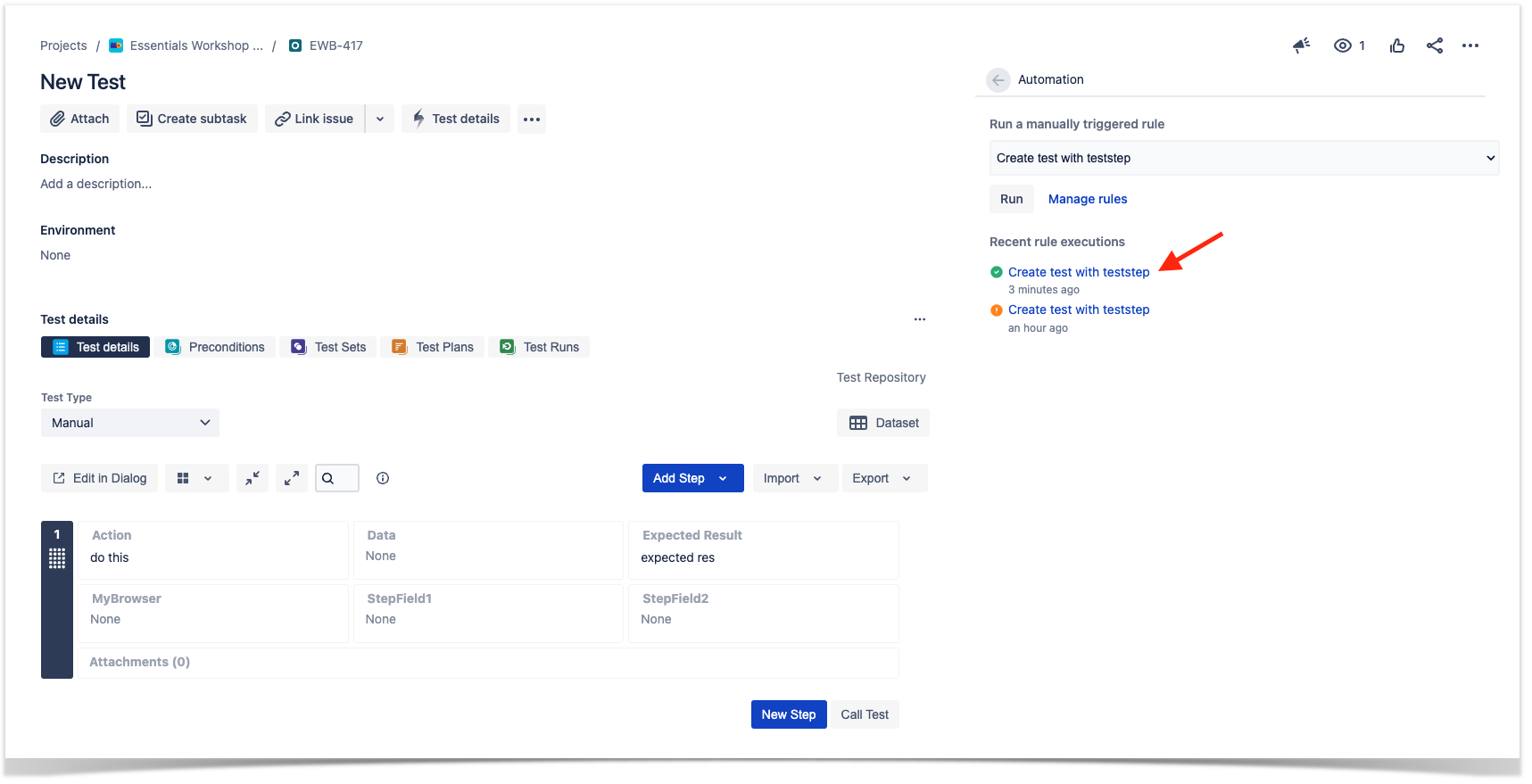
This will take us to the Automation rule details page where we can access the Audit log of that rule.
This option will load all the actions performed over the rule and we can have some more details if we press the "Show more" option.